Transparency label: AI-assisted. NotebookLM worked with Nishigaya’s post to outline the five levels.
In a recent post on SubStack, Nori Nishigaya wrote:
Being effective in your use of AI isn’t just figuring out the ideal prompt. There’s so much that goes into skillful use of AI. Done poorly, it can become a tool for chaos. This post lays out the framework that I’ve been exploring as a way of taming this chaos and getting really powerful results from AI.
His framework captures the moment perfectly, and it resonates with my own learning and experience. Nishigaya’s beautifully clear explanation, which identifes the five levels outlined below, is a powerful (though deceptively simple) aid to thinking about the human | AI interaction.
See also this infographic or this one or this one, all produced by NotebookLM.
In my (small-scale) project to develop an agent for a recruitment agency, I am currently working at Levels 1 to 3. Once the harness has proved its worth, we’ll explore Level 4.
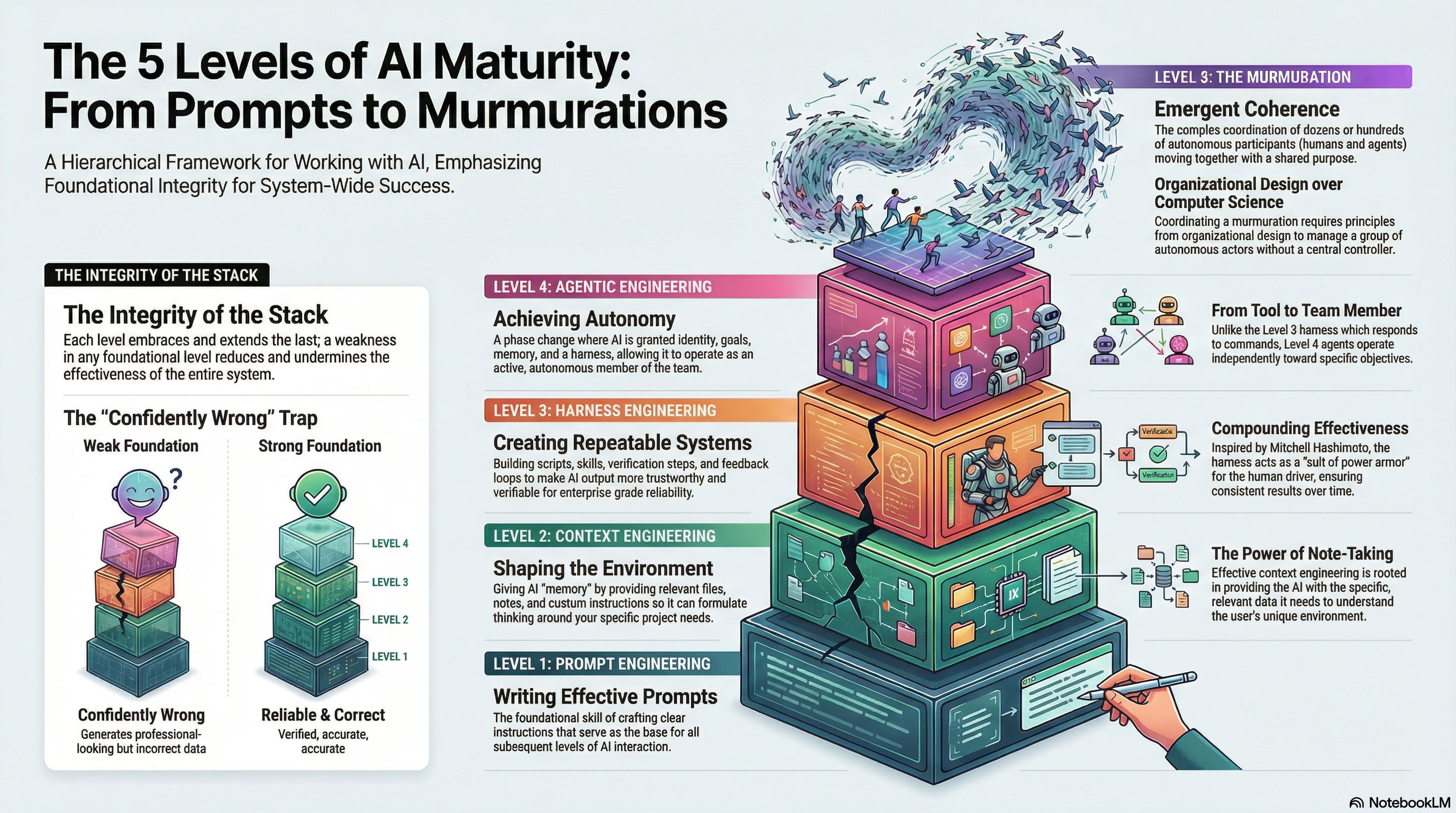
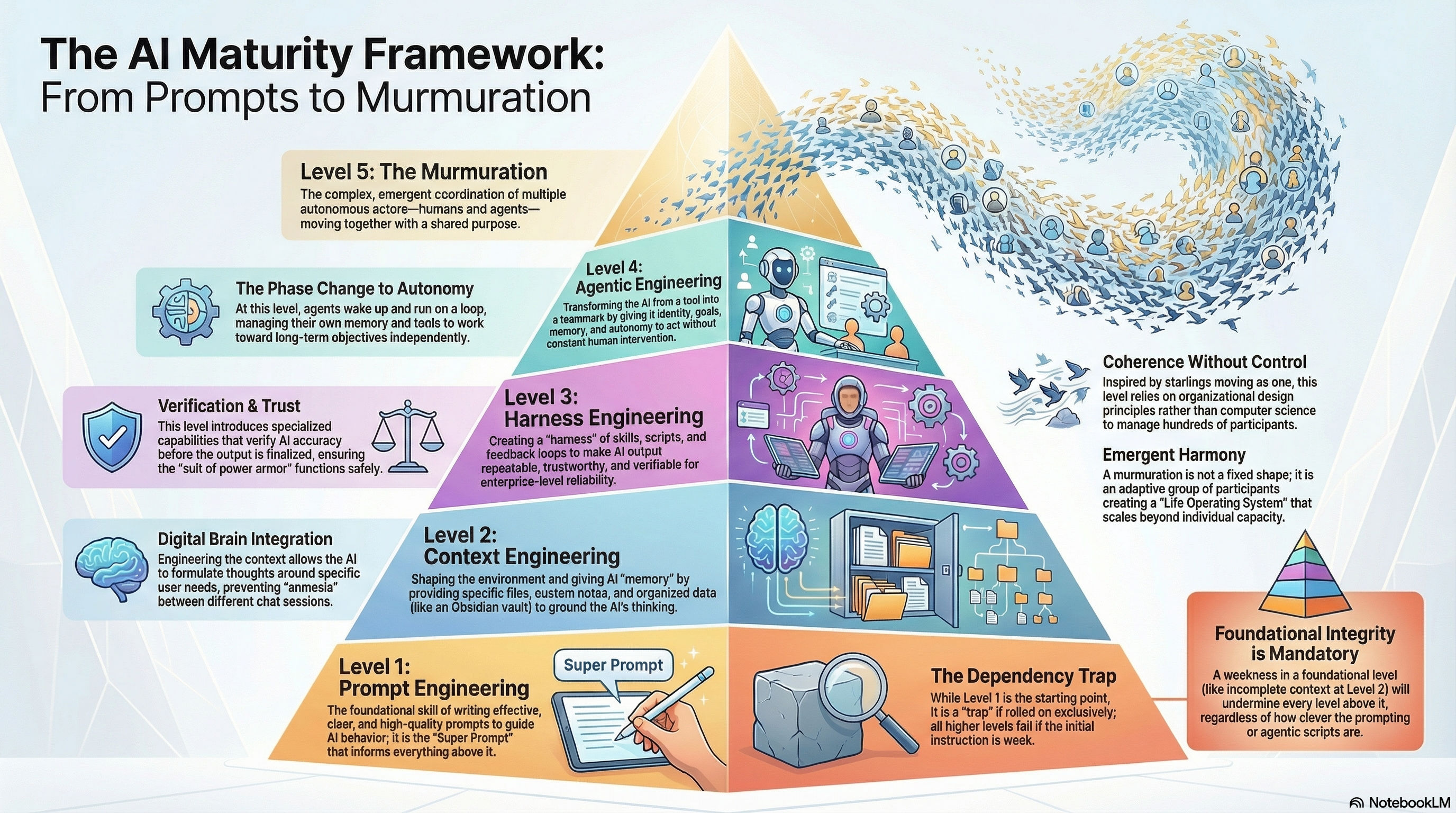
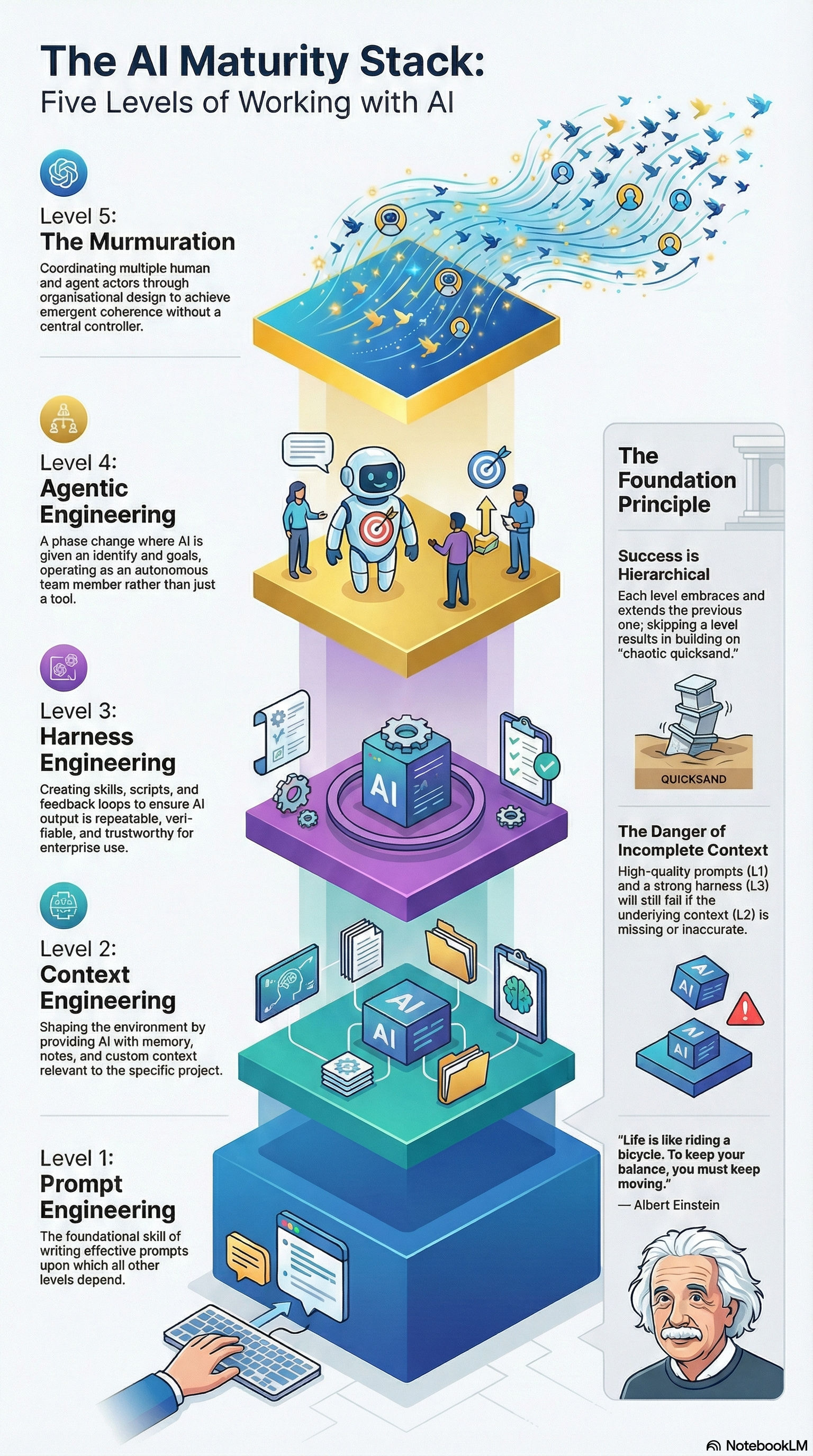
The Five Levels of Working with AI
Produced by NotebookLM from Nishigaya’s post
Level 1: Prompt Engineering – The foundational skill of writing effective prompts.
Level 2: Context Engineering – Shaping the environment and giving AI memory by providing custom context, files, and notes so the AI can formulate its thinking around your specific needs.
Level 3: Harness Engineering – Creating skills, scripts, verification steps, and feedback loops to make AI output more repeatable, trustworthy, and verifiable.
Level 4: Agentic Engineering – Deploying autonomous agents equipped with identity, goals, memory, and a strong harness, transforming them from a tool into an active, autonomous member of a team.
Level 5: The Murmuration – The complex coordination of multiple autonomous actors (both humans and agents) moving together with emergent coherence and a shared purpose, drawing on principles from organizational design.
{kind=link}
{kind=link}
{kind=link}
{kind=link}